Character Set/charset
- set of characters that may or may not define an encoding- Examples: ASCII (covers all English characters), ISO/IEC 646, Unicode (covers characters from all living languages in the world)
Encoding/Character encoding/Character set encoding
- General meaning: a set of rules or system for representing a character in some form such as bit pattern, sequence of natural numbers, octets, or electrical pulses, e.g. Morse code, Baudot code, ASCII and Unicode- More strict meaning: a mapping of characters to how they are stored in memory (bit sequence)
- Examples: ASCII encoding, Unicode encodings like UTF-8 and UTF-16
Source of Encoding Standards:
- Standards bodies
ANSI (American National Standards Institute)
- is the U.S. standards organization that creates standards (like the ASCII) for the computer industry
ISO (International Organization for Standardization)
- largest developer of voluntary International Standards
- adopted ASCII as ISO 646:IRV - Independent software vendors
IBM
- developed codepage 437 for DOS, codepage 852 for Eastern European languages that use Latin script, codepage 855 for Russian and some other Eastern European languages that use Cyrillic script, etc.
Windows
- developed the familiar Windows codepages, such as codepage 1252, alternately known as "Western", "Latin 1" or "ANSI"
Examples of character sets or encodings
- is a 7-bit encoding scheme used to encode letters, numerals, symbols, and device control codes as fixed-length codes using integers
- includes definitions for 128 characters
- 128 to 255 is free causing varied character representation of 128 to 255 resulting to varied ASCII extensions
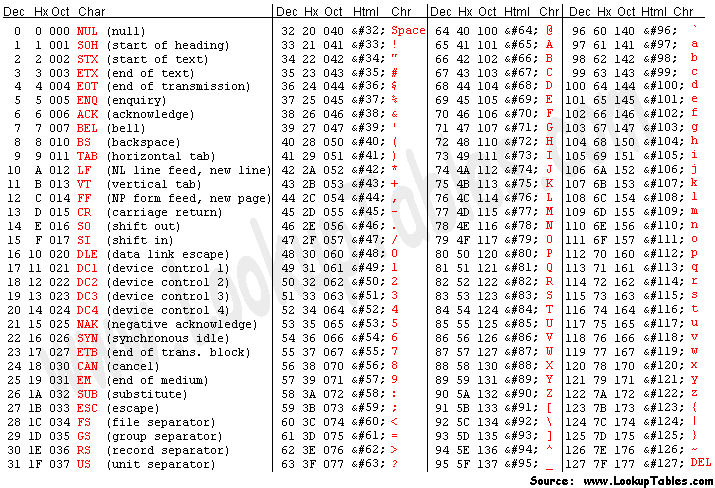
EBCDIC (Extended Binary Coded Decimal Interchange Code)
- is an 8-bit character encoding used mainly on IBM mainframe and IBM midrange computer operating systems.

Codepage 1252 and ISO 8859-1
- ISO 8859-1 “Latin 1” is a standard developed by American National Standards Institute (ANSI)
- Codepage 1252 is a standard created by the Microsoft for Western European languages based on an early draft of the ANSI proposal that later became ISO 8859-1 “Latin 1”
- Codepage 1252 was finalised before ISO 8859-1 was finalised, however, and the two are not the same: Codepage 1252 is a superset of ISO 8859-1
ANSI codepage
- Microsoft referred Codepage 1252 as "the ANSI codepage" but around the time of Windows 95 development, Microsoft began to use the term "ANSI" in a different sense to mean any of the Windows codepages, as opposed to Unicode
- currently in the context of Windows, the terms "ANSI text" or "ANSI codepage" should be understood to mean text that is encoded with any of the legacy 8-bit Windows codepages rather than Unicode. It really should not be used to mean the specific codepage associated with the US version of Windows, which is Codepage 1252.
Other Legacy encoding standards
- most encode each character in terms of a single 8-bit processing unit, or byte
- some are double-byte encodings like Microsoft codepages for Chinese, Japanese and Korean
UTF-8 and Unicode
Unicode
- is a standard developed by the Unicode Consortium that assigns a unique number/identifier for every character, no matter what the platform, no matter what the program, no matter what the language
- In Unicode, every character is assigned a unique number called "code point"
Ways of Encoding Unicode
- UCS-2 (because it has two bytes) - the traditional store-it-in-two-byte methods
- UTF-16 (because it has 16 bits) - you have to figure out if it's high-endian UCS-2 (most significant byte first) or low-endian UCS-2 (least significant byte first) through the BOM (byte-order mark)
- UTF-8 (Unicode Transformation Format 8-bit)
- is a variable-width encoding that can represent every character in the Unicode character set. It was designed for backward compatibility with ASCII and to avoid the complications of endianness and byte order marks in UTF-16 and UTF-32 - UTF-7 - similar to UTF-8 but guarantees that the high bit will always be zero
- UCS-4 - stores each code point in 4 bytes
Other related terms
Code Page
- is a term that originated from IBM that essentially means the same as character set and encodingInternationalized URL / URL encoding / Percent encoding
- see https://www.w3.org/International/articles/idn-and-iri/, http://www.url-encode-decode.com/Sources:
http://www.unicode.org/
http://en.wikipedia.org
http://www.joelonsoftware.com/articles/Unicode.html
http://scripts.sil.org/cms/scripts/page.php?item_id=IWS-Chapter03
http://mikesusan.com/ascii.html
http://www.utf-8.com/
http://kunststube.net/encoding/